One of the perks of working at Case Western Reserve is that we often qualify for access to cutting edge resource and special projects. In this case, since our digital histology deep learning work requires a large number of GPUs to analyze thousands of patients, we were granted access to the OSC Ruby cluster, which has 20 NVIDIA Tesla K40 GPUs. Since the cluster has only recently been setup, there was some leg work required on our end to get Caffe fully up and running, without root access, which we’ll document here.
Module Setup
Ruby supports the Module package for dynamic load and unloading of resources. Its quite handy as a way to manage different versions of the same software and to keep the associated BASH variables sane. We’ll leverage that package, and create our own module file, for our dependencies. Firstly, we need to see what things are already installed:

Looking at the list, we see can already see some packages that we’ll need to load up to meet the Caffe dependencies. We want:
- python/2.78
- cuda/6.5.14
- matlab/r2014b
- boost/1.56.0
- mkl/11.2.0
We can add these to a common module file so that they’re loaded all the time at user login (since we’ll not be using this cluster for anything else). To do so, we make a set of directories from our home directory of the format (where my username is cwr0463):
/nfs/01/cwr0463/.usr/local/share/modulefiles
And create a file called common and simply add the module load commands:
- module load python/2.7.8
- module load cuda/6.5.14
- module load matlab/r2014b
- module load boost/1.56.0
- module load mkl/11.2.0
Now to make sure that these modules are loaded during start up, we edit ~/.profile and add the following:
- module use -a /nfs/01/cwr0463/.usr/local/share/modulefiles
- module load common
Which first tells module to add our modulefiles directory as a place to look for module files, and then subsequently to load the module called “common” that we just made.
Installing Other Packages
Now we’ll need to git the latest versions of many of the other dependencies which aren’t already in the system. We’ll list the commands here and then discuss how to install them:
- git clone https://github.com/Itseez/opencv.git
- git clone https://github.com/google/leveldb.git
- git clone https://github.com/schuhschuh/gflags.git
- git clone https://github.com/google/protobuf.git
- git clone https://github.com/google/glog.git
- git clone https://gitorious.org/mdb/mdb.git
- git clone https://github.com/google/snappy.git
For each of them, we proceed in a similar manner, as each requires compiling and to either use make or cmake.
- run autogen.sh, if available
- if using Make (“configure” file is present) run:
- ./configure --prefix=/nfs/01/cwr0463/.usr/local/
- else (using Cmake),
- mkdir build, cd build, cmake -DCMAKE_INSTALL_PREFIX=/nfs/01/cwr0463/.usr/local/ ..
- make
- make install
Notice that we specify a usr level directory for installation of the libraries, since we don’t have root access.
There are some small caveats, listed below:
LevelDB: doesn’t have a “make install”, so the files must be done manually:
- cp --preserve=links libleveldb.* /nfs/01/cwr0463/.usr/local/
- cp -r include/leveldb /nfs/01/cwr0463/.usr/local/include
MDB: doesn’t have a ./configure or cmake, so we need to edit the Makefile and change the installation prefix directly:
- prefix = /nfs/01/cwr0463/.usr/local/
Gflags: error while trying to use gflags when not compiled with –fPIC, which I posted a solution to here. Simply, after running Cmake:
- Edit CMakeCache.txt
- Change:
- CMAKE_CXX_FLAGS:STRING=-fPIC
- Proceed as normal
Add new dependencies to module file
Afterwards, we have all of the dependencies installed into ~/.usr/local and it looks something like this:
- -bash-4.1$ pwd
- /nfs/01/cwr0463/.usr/local
- -bash-4.1$ ls
- bin include lib man share src
Now we need to add these paths to our environmental variables, so that compilers and programs can find them. We’ll again leverage a module file for this. We’ll make a new module called “depends_aj”, short for dependencies, and my initials 🙂 We can do this by making a directory called depends_aj inside of /nfs/01/cwr0463/.usr/local/share/modulefiles and then in that directory adding a file 1.0 to indicate it’s the first version. So it looks something like this:
- -bash-4.1$ pwd
- /nfs/01/cwr0463/.usr/local/share/modulefiles
- -bash-4.1$ find .
- .
- ./depends_aj
- ./depends_aj/1.0
- ./common
Inside of the file 1.0, we put the variable adjustment commands like so:
- -bash-4.1$ cat 1.0
- set root /nfs/01/cwr0463/.usr/local/
- prepend-path PATH $root/bin
- prepend-path CPLUS_INCLUDE_PATH $root/include
- prepend-path C_INCLUDE_PATH $root/include
- prepend-path LD_LIBRARY_PATH $root/lib
- prepend-path LIBRARY_PATH $root/lib
- prepend-path MANPATH $root/share
Which we can see will add our binaries, libraries and includes to the path for compilers to find easily (in the next step). Lastly, we’ve done all of this hardwork, it’d be nice if this module was also loaded automatically on startup, so we add the line “module load depends_aj/1.0” to the common file we created earlier.
I know ahead of time that I’d like to use cuDNN. At the time of this writing Caffe only supports V1, so we download that and stick the library files into $root/lib with other files and the .h file into $root/include as well.
Finally, all done! Now onto Caffe!
Compiling Caffe
Of course to begin, we need the source code so we use:
- git clone https://github.com/BVLC/caffe.git
To pull the latest revision from the master branch.
As suggested, we create a makefile config from the template:
- cp Makefile.config.example Makefile.config
And then proceed to put in our values, which we will discuss in batches.
Firstly, we want to enable cuDNN, a highly optimized DL library:
- < # USE_CUDNN := 1
- ---
- > USE_CUDNN := 1
Since there are multiple installations of cuda on the system, we need to point it at the correct one:
- < CUDA_DIR := /usr/local/cuda
- ---
- > CUDA_DIR := /usr/local/cuda/6.5.14
Since we have mkl available, might as well use it (remember we’ve loaded the module for it before):
- < BLAS := atlas
- < # Custom (MKL/ATLAS/OpenBLAS) include and lib directories.
- ---
- > BLAS := mkl
- > # Custom (MKL/ATLAS/OpenBLAS) include and lib directories
Again, multiple matlabs, so we point at the one we’ll be using
- < # MATLAB_DIR := /usr/local
- ---
- > MATLAB_DIR := /usr/local/MATLAB/R2014b/
Ruby seems to have (multiple) versions of anaconda python, so we find the one we’re using and stick in its path:
- < PYTHON_INCLUDE := /usr/include/python2.7 \
- < /usr/lib/python2.7/dist-packages/numpy/core/include
- ---
- > #PYTHON_INCLUDE := /usr/include/python2.7 \
- > # /usr/lib/python2.7/dist-packages/numpy/core/include
- < # Verify anaconda location, sometimes it's in root.
- < # ANACONDA_HOME := $(HOME)/anaconda
- < # PYTHON_INCLUDE := $(ANACONDA_HOME)/include \
- < # $(ANACONDA_HOME)/include/python2.7 \
- < # $(ANACONDA_HOME)/lib/python2.7/site-packages/numpy/core/include \
- ---
- > # Verify anaconda location, sometimes it's in root.
- > ANACONDA_HOME := /usr/local/anaconda/anaconda2/
- > PYTHON_INCLUDE := $(ANACONDA_HOME)/include \
- > $(ANACONDA_HOME)/include/python2.7 \
- > $(ANACONDA_HOME)/lib/python2.7/site-packages/numpy/core/include \
- ---
- < PYTHON_LIB := /usr/lib
- < # PYTHON_LIB := $(ANACONDA_HOME)/lib
- ---
- > #PYTHON_LIB := /usr/lib
- > PYTHON_LIB := $(ANACONDA_HOME)/lib
And lastly, we want to modify the include and library files:
- < INCLUDE_DIRS := $(PYTHON_INCLUDE) /usr/local/include
- < LIBRARY_DIRS := $(PYTHON_LIB) /usr/local/lib /usr/lib
- ---
- > INCLUDE_DIRS := $(PYTHON_INCLUDE) /usr/local/include $(subst :, ,$(INCLUDE))
- > LIBRARY_DIRS := $(PYTHON_LIB) /usr/local/lib /usr/lib $(subst :, ,$(LD_LIBRARY_PATH))
We see that we add the directories which were modified for us by the module package. This was a bit tricky though because i expected Make to split the path by the double colon ( “:” ), but it didn’t, so i used a string replace function to replace the double colon with spaces, and then things worked fine.
FYI, the easiest way to find out which variables are changed by the loaded module is to use the command “module display [modulefile name]”. So for example:
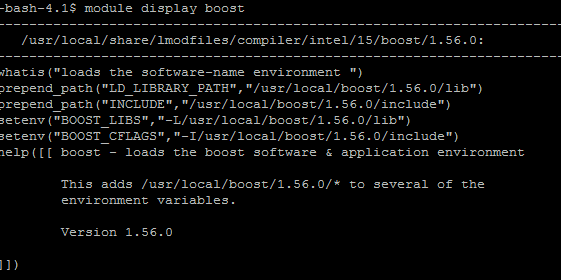
This shows us both the include path and the library path for boost are added to our enviromental variables, which we used directly the makefile.
Python Library Compilation
We also use the python module, so we needed to compile that as well. First we went into the python directory and used:
- for req in $(cat requirements.txt); do pip install --user $req; done
To install, in the user space, all of the necessary requirements (of which I think only 1 or 2 weren’t previously available). And then used make pycaffe, and things worked out wonderfuly!
Testing Installation
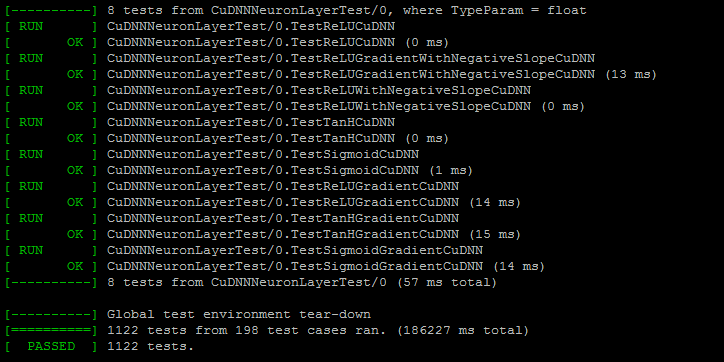
With that all in place, we do a make all. Afterwards, we request a GPU enabled node and run make runtest to ensure that the system is indeed operating the way we expect it to before we throw real world data at it. In our case, everything worked out as expected!
We can do this quite easily by using a debug node, which is specifically available for short term jobs:
- qsub -I -l nodes=1:ppn=1:gpus=2 -q debug
And we can see, all the tests have passed! Success!
Last but not least, 2 other tasks to make the new environment feel like home:
- Setup Keyless SSH
- Install Tmux
Total time from beginning to end was about 4 hours, and man do those GPUs kick some serious ass!
Super, thanks for your contribution, Andrew!
Hi Andrew, Thank you so much for sharing your experience on configuring Caffe on HPC cluster and it’s great to know it works. I’m curious whether Caffe can use all the 20 GPUs on HPC or not? Based on what I read from Caffe related discussions, Caffe can’t train models in distributed mode (across GPUs on a cluster in different nodes). Could you take a look the GPU utilization when you are training model on the HPC with Caffe?
No, unfortunately, caffe is not currently designed to do distributed training, allowing the use of all 20 “together”. What you can do, for example, is use a single node to train a model, and then use all 20 GPUs to produce output in parallel, such that each GPU works on a different image.
Thank you for your reply! Do you know the Nvidia DIGITS project (https://developer.nvidia.com/digits)? There is a Nvidia team that figured out how to use Caffe on multiple GPUs but still on the same machine. They provide a devbox (https://developer.nvidia.com/devbox) that built with 4 GPUs that can be used by Caffe at the same time. I don’t know your HPC structure, but I think it might be worthwhile to try DIGITS on it and see how many GPUs it can use. (It’s pretty straight forward to configure)
Thanks for your comments! I am familiar with it. Did you know its backend is actually Caffe? : ) Because of that, I think you might have misunderstood the capability of Digits though, their site says (http://devblogs.nvidia.com/parallelforall/easy-multi-gpu-deep-learning-digits-2/): “DIGITS can train multiple networks on the same data set in parallel, or train the same network on multiple datasets in parallel.”. This means it doesn’t support spreading the training of a single network on a single data set to multiple GPUs. I expect when caffe implements it, digits will have it implemented immediately afterward. One of the caffe tickets is here: https://github.com/BVLC/caffe/issues/876. Regardless, the HPC i’m using has 1 GPU per node, so unfortunately i expect it to be some time before there is an out of the box support for cross-machine training
Yes, thank you for your information. I know DIGITS is based on Caffe. In the next paragraph of the words you quoted, there is graph showed the training time comparison on different number of GPUs (same data set, same model config, different number of GPUs). The demo video on https://developer.nvidia.com/digits also showed how to use multiple GPUs on training a single model with one dataset (from 1:40). Looks like Nvidia has figured out how to use caffe on multiple GPUs but the Caffe project hasn’t add this feature. I also commented this on the ticket. But it seems there still long way to go to get Caffe work GPUs from different nodes.
Very interesting, thanks for pointing that out!! You can find the digits ticket here: https://github.com/NVIDIA/DIGITS/issues/92 it seems that they have forked and modified their own version of caffe. I guess caffe will have it quite soon then : ) I’ve added the link to your comment on github.