
This blog posts explains how to train a deep learning nuclear segmentation classifier in accordance with our paper “Deep learning for digital pathology image analysis: A comprehensive tutorial with selected use cases”.
Please note that there has been an update to the overall tutorial pipeline, which is discussed in full here.
This text assumes that Caffe is already installed and running. For guidance on that you can reference this blog post which describes how to install it in an HPC environment (and can easily be adopted for local linux distributions).
Background
Nuclei segmentation is an important problem for two critical reasons: (a) there is evidence that the configuration of nuclei is correlated with outcome [2], and (b) nuclear morphology is a key component in most cancer grading schemes [27],[28]. A recent review of nuclei segmentation literature [29] shows that detecting these nuclei tends not to be extremely challenging, but accurately finding their borders and/or dividing overlapping nuclei is the current challenge. The overlap resolution techniques are typically applied as post-processing on segmentation outputs, and thus outside of the scope of this tutorial.
We have specifically chosen to look at the problem of detecting nuclei within H&E stained estrogen receptor positive (ER+) breast cancer images. Breast cancer nuclei are, in my opinion, the most challenging to work with because of their large variances in appearance as compared to other organs. For example, the area of a breast cancer nucleus can vary by over 200% and have notable differences in texture, morphology, and stain absorption. These differences imply that developing a single hand-crafted approach that works well across all cases is challenging. We find that on our dataset we can obtain f-scores in the range of ~.83, without any post-processing, making this DL approach comparable to sophisticated handcrafted approaches.
Overview
We break down this approach into 5 steps:
Step 1: Patch Extraction (Matlab): extract patches from all images of both the positive and negative classes
Step 2: Cross-Validation Creation (Matlab): at the patient level, split the patches into a 5-fold training and testing sets
Step 3: Database Creation (Bash): using the patches and training lists created in the previous steps, create 5 sets of leveldb training and testing databases, with mean files, for high performance DL training.
Step 4: Training of DL classifier (Bash): Slightly alter the 2 prototxt files used by Caffe, the solver and the architecture to point to the correct file locations. Use these to train the classifier.
Step 5: Generating Output on Test Images (Python): Use final model to generate the output
There are, of course, other ways of implementing a pipeline like this (e.g., use Matlab to directly create a leveldb, or skip the leveldb entirely, and use the images directly for training) . I’ve found using the above pipeline fits easiest into the tools that are available inside of Caffe and Matlab, and thus requires the less maintenance and reduces complexity for less experienced users. If you have a suggested improvement, I’d love to hear it!
Dataset Description
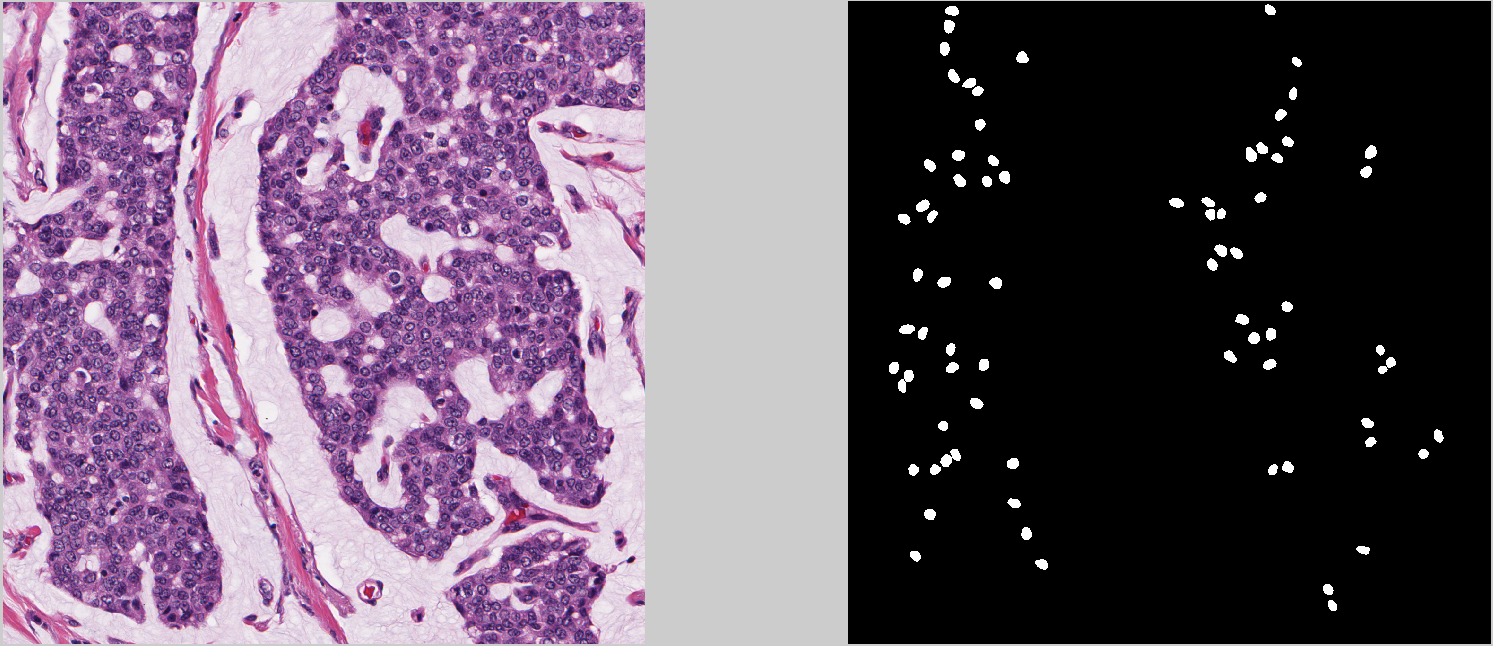
The dataset consist of 143 images ER+ BCa images scanned at 40x. Each image is 2,000 x 2,000. Across these images there are about 12,000 nuclei manually segmented. The format of the files is:
12750_500_f00003_original.tif: original H&E image
12750_500_f00003_mask.png: mask of the same size, where white pixels are nuclei
Each image is prefaced by a code (e.g., “12750”) to the left of the first underscore (_), which coincides with a unique patient number. A few patients have more than 1 image associated with them (137 patients vs 143 images), so make sure to split them into training and testing sets at the patient level, not the image level.
The data and the associated masks are located here (1.5G).
Examples of these images and their annotates can be seen below


Step 1: Patch Extraction (Matlab)
We refer to step1_make_patches.m, which is fully commented.
A high level understanding is provided here:
- Break the images into groups by patient ID number.
- For each image, load the annotation image, create an edge mask and compute a negative class mask which is likely to not have nuclei (since we can’t be sure as the entire image isn’t annotated)
 Original Image |
 Partially Annotated Image |
 Estimated Background Region |
 Nuclei Edge Pixels |
The file name format for each patch is as follows:
u_v_w_x_y_z.png — > example 10256_1_0_e_1_0.png
Where u is the patient ID, v is the image number of the patient, w is the class (0 (non nuclei) or 1 (nuclei)), x is the type of patch (“e” is edge, “b” is background (i.e., stroma), “p” is positive), y is the number of the patch (1 to 2500), and z is rotation (0 or 90 in this case).
- From each of these, randomly crop patches, save them to disk. At the same time, we maintain a “patient_struct”, which contains all of the file names which have been written to disk.
Step 2: Cross-Validation Creation (Matlab)
Now that we have all of the patches written to disk, and we have all of the file names saved into patient_struct, we want to split them into a cross fold validation scheme. We use step2_make_training_lists.m for this, which is fully commented.
In this code, we use a 5-fold validation, which is split at the patient level. Again, remember splitting at the image level is unacceptable if multiple images can come from the same patient!
For each fold, we create 4 text files. Using fold 1 as an example:
train_w32_parent_1.txt: This contains a list of the patient IDs which have been used as part of this fold’s training set. This is similar to test_w32_parent_1.txt, which contains the patients used for the test set. An example of the file content is:
10256
10260
10261
10262
train_w32_1.txt: contains the filenames of the patches which should go into the training set (and test set when using test_w32_1.txt). The file format is [filename] [tab] [class]. Where class is either 0 (non-nuclei) or 1 (nuclei). An example of the file content is:
10256_1_0_e_1_0.png 0
10256_1_0_e_1_90.png 0
10256_1_0_e_2_0.png 0
10256_1_0_e_2_90.png 0
10256_1_0_e_3_0.png 0
10256_1_0_e_3_90.png 0
All done with the Matlab component!
Step 3: Database Creation (Bash)
Now that we have both the patches saved to disk, and training and testing lists split into a 5-fold validation cohort, we need to get the data ready for consumption by Caffe. It is possible, at this point, to use an Image layer in Caffe and skip this step, but it comes with 2 caveats, (a) you need to make your own mean-file and ensure it is in the correct format and (b) an image layer can is not designed for high throughput. Also, having 100k+ files in a single directory can bring the system to its knees in many cases (for example, “ls”, “rm”, etc), so it’s a bit more handy to compress them all in to 10 databases (1 training and 1 testing for 5 folds), and use Caffe’s tool to compute the mean-file.
For this purpose, we use this bash file: step3_make_dbs.sh
We run it in the “subs” directory (“./” in these commands), which contains all of the patches. As well, we assume the training lists are in “../”, the directory above it.
Here we’ll briefly discuss the general idea of the commands, while the script has additional functionality (computes everything in parallel for example).
Creating Databases
We use the caffe supplied convert_imageset tool to create the databases using this command:
~/caffe/build/tools/convert_imageset -shuffle -backend leveldb ./ DB_train_1
We first tell it that we want to shuffle the lists, this is very important. Our lists are in patient and class order, making them unsuitable for stochastic gradient descent. Since the database stores files, as supplied, sequentially, we need to permute the lists. Either we can do it manually (e.g., use sort –random) , or we can just let Caffe do it 🙂
We specify that we want to use a leveldb backend instead of a lmdb backend. My experiments have shown that leveldb can actually compress data much better without the consequence of a large amount of computational overhead, so we choose to use it.
Then we supply the directory with the patches, supply the training list, and tell it where to save the database. We do this similarly for the test set.
Creating mean file
To zero the data, we compute mean file, which is the mean value of a pixel as seen through all the patches of the training set. During training/testing time, this mean value is subtracted from the pixel to roughly “zero” the data, improving the efficiency of the DL algorithm.
Since we used a levelDB database to hold our patches, this is a straight forward process:
~/caffe/build/tools/compute_image_mean DB_train_1 DB_train_w32_1.binaryproto -backend leveldb
Supply it the name of the database to use, the mean filename to use as output and specify that we used a leveldb backend. That’s it!
Step 4: Training of DL classifier (Bash)
Setup files
Now that we have the databases, and the associated mean-files, we can use Caffe to train a model.
There are two files which need to be slightly altered, as discussed below:
BASE-alexnet_solver.prototxt: This file describes various learning parameters (iterations, learning method (Adagrad) etc).
On lines 1 and 10 change: “%(kfoldi)d” to be the number of the fold for training (1,2,3,4,5).
On line 2: change “%(numiter)d” to number_test_samples/128. This is to have Caffe iterate through the entire test database. Its easy to figure out how many test samples there are using:
“wc –l test_w32_1.txt”
BASE-alexnet_traing_32w_db.prototxt: This file defines the architecture.
We only need to change lines 8, 12, 24, and 28 to point to the correct fold (again, replace “%(kfoldi)d” with the desired integer). That’s it!
Note, these files assume that the prototxts are stored in a directory called ./model and that the DB files and mean files are stored in the directory above (../). You can of course use absolute file path names when in doubt.
In our case, we had access to a high performance computing cluster, so we used a python script (step4_submit_jobs.py) to submit all 5 folds to be trained at the same time. This script automatically does all of the above work, but you need to provide the working directory on line 11. I use this (BASE-qsub.pbs) PBS script to request resources from our Torque scheduler, which is easily adaptable to other HPC environments.
Initiate training
If you’ve used the HPC script above, things should already be queued for training. Otherwise, you can start the training simply by saying:
~/caffe/build/tools/caffe train –solver=1-alexnet_solver_ada.prototxt
In the directory which has the prototxt files. That’s it! Now wait until it finishes (600,000) iterations. 🙂
Step 5: Generating Output on Test Images (Python)
At this point, you should have a model available, to generate some output images. Don’t worry, if you don’t, you can use mine.
Here is a python script, to generate the test output for the associated k-fold (step5_create_output_images_kfold.py).
It takes 2 command line arguments, base directory and the fold.
The base directory is expected to contain:
BASE/images: a directory which contains the tif images for output generation
BASE/models: a directory which holds the 5 models (1 for each fold)
BASE/test_w32_parent_X.txt: the list of parent IDs to use in creating the output for fold X=1,2,3,4,5, created in step 2
BASE/DB_train_w32_X.binaryproto: the binary mean file for fold X=1,2,3,4,5, created in step 3
It generates 2 output images for each input. A “_class” image and a “_prob” image. The “_prob” image is a 3 channel image which contains the likelihood that a particular pixel belongs to the class. In this case, the Red channel represents the likliehood that a pixel belongs to the non-nuclei class, and the green channel represents the likelihood that a pixel belongs to the nuclei class. The two channels sum to 1. The “_class” image is a binary image using the argmax of the “_probs image”.
 |
 |
 |
| Input Image | _class image | _prob image |
Typically, you’ll want to use a validation set to determine an optimal threshold as it is often not .5 (which is equivalent to argmax). Subsequently, use this threshold on the the “_prob” image to generate a binary image.
Final Notes
Efficiency in Patch Generation
Writing a large number of small, individual files to a harddrive (even SSD) is likely going to take a very long time. Thus for Step 1 & Step 2, I typically employ a ram disk to drastically speed up the processes. Regardless, make sure Matlab does not have the output directory in its search path, otherwise it will likely crash (or come to a halt), while trying to update its internal list of available files.
As well, using a Matlab Pool (matlabpool open), opens numerous workers which also greatly speed up the operation and is recommended as well.
Efficiency in Output Generation
It most likely will take a long time to apply a the classifier pixel wise to an image to generate the output. In actuality, there are many ways to speed up this process. The easiest way is to identify pixels in the image which are very unlikely to belong to the nuclei class (for example, low absorption of hematoxylin dye as determined via color deconvolution) and exclude those from computation.
Keep an eye out for future posts where we delve deeper into this and provide the code which we use!
Magnification
It is very important to use the model on images of the same magnification as the training magnification. This is to say, if your patches are extracted at 40x, then the test images need to be done at 40x as well.
Code is available here
Data is available here (1.5G)
Hi Andrew!
This is a great tutorial!
Quick question: if I wanted to try this tutorial out on my own data, would my images have to be of the same size and type as the images used here?
Ie, 2000×2000 pixel images, one of the format PNG and one TIFF?
The images I’d like to work with are 1024×1024 PNGs.
What is more important is to make sure that the images are of the same magnification. If you want to change the image size, you can do that, but that depends on which version of the code you’re looking at. This version is quite slow and i don’t think requires any change, this one is significantly faster and requires a change of the prototxt. The lastest verion of the output generation code in my github should be runable without any modifications, but there is no associated blog post, but should be pretty easily understandable from the command line options
Why are the nucleis not all annotated in one single image?
As discussed in the paper, annotating all the nuclei in all images was too laborious for our expert. If you can annotate them all, I’d be happy to host them 🙂
Completely understandable that you couldn’t annotate all of the images- but how did you train without exhaustive GT?
take a look at the code : )
Since the images are not fully annotated, how to compute the F-score? I mean, it must have high false positive since an nuclei may not be annotated in the label image.
I think if you read the manuscript carefully it says that the f-score was computed on a per nuclei basis for all nuclei which were annotated. so we took each in the ground truth and compared it individually to the nuclei our DL returned and computed the f-score and then took the mean f-score. it was unfortunately impossible to annotate all the nuclei across all 140 or so images, annotating the ones we presented (~1,000 if i remember correctly) already took about 80 hours of work
Thanks for your response, I get it.
Thanks for sharing your work. I’m just wondering why dividing folds on the patient level is so important. How much of a difference would it make if you pooled the patches together on the image level? I’m guessing patches from the same patient would validate higher, but would it be significant? Have you ever encountered a case where you have many images from a small number of patients?
Thanks for your help and your hard work.
it makes a *huge* difference! disease tend to present very similarly intra-patient and very different inter-patient, thus using the same patient in both the training and testing set is essentially like testing directly on the training set, leading to a very highly inflated accuracy that won’t be sustained when a new patient is presented to the system (since you haven’t trained on any of their patches).
Hi. Why did you say you used AlexNet architecture in you paper while the network in the code is LeNet5? I am sorry but I just wanna make sure it is not a mistake I am understanding!
i think you’ll find its based off of this, provided by caffe: https://github.com/BVLC/caffe/tree/master/models/bvlc_alexnet overall, though, the networks are very similar
Why do you say they are similar? AlexNet has 5 convolutions while CIFAR10 has 3 convolutions. They are different. In the codes, the architecture is CIFAR10 while in paper it is AlexNet. I just wanna make sure I am not misunderstood. Many thanks:)
However, I really wanna appreciate your effort in putting these information. I was new to histology and I got lots of information. Can I ask what is the reference of the dataset? Many thanks in advance for your replies.
glad i could help, but what do you mean by “reference of the dataset”?
I mean is the database from for example AMIDA13?? where is it from? Not just this one but the dataset used in other tasks. I tried to find the reference for the dataset used but did not find. Is it a private data set or what?
Our group curated it and performed the annotations, so it was a private dataset, but now has been made public 🙂
Hello!
I have finally installed caffe and have it working. Now, i try to run: “python step5_create_output_images_kfold.py lyphocyte 2” which gives me the following output: https://docs.google.com/document/d/1J5rUgIel3u5Li9N5_7J5W1NeKIsk4-BciQgrd4Dv3r8/edit?usp=sharing
Have you ever came across this error? Any help would be appreciated. Thank you!
Are you sure you’ve used the correct binary model? this error “Cannot copy param 0 weights from layer ‘ip2’; shape mismatch. Source param shape is 2 64 (128); target param shape is 3 64 (192). To learn this layer’s parameters from scratch rather than copying from a saved net, rename the layer.” indicates that ip2, which is the final fully connected layer before the softmax, has a dimension of 2×64 which is suitable for a 2-class problem, while the expected value should be 3×64. In this case, the lymphoma use case contains 3 classes, so the model itself should be 3×64 not the 2×64 that its reporting. So either i’ve uploaded the wrong model, or you’ve downloaded the wrong model 🙂 or you’re using an incorrect model definition. i’m now noticing that this is on the nuclei page, which is a 2 class problem, but the network you sent is designed for 3 classes?
Thank you you are correct! I had downloaded the incorrect models. I have now downloaded the correct models and the code runs!
what can i say, i’m a pro 😉
also, after you get your feet wet, you should switch over to this type of approach, MUCH faster: http://www.andrewjanowczyk.com/revised-deep-learning-approach-using-matlab-caffe-python/
When I run step5_ I receive this error (the ste5_ file follows the error code): https://docs.google.com/document/d/1l0HsufA6Ie-2uMnQWy9ulqtJbWmn-IWEtu6m7rheJBY/edit
I am unsure what the problem is. I have tried specifying a complete and a partial path but neither seems to work.
It is possible that I do not fully understand the code and this is a simple fix…
I commented out the largest for loop in the code because I am only attempting to apply step5_ to one image.
Any assistance would be appreciated. Thank you again! You’re great!
does the subdirectory exist? https://stackoverflow.com/questions/6134883/caught-ioerror-while-rendering-no-such-file-or-directory-error-when-trying-to
Hi!
Dan, where did you get the correct models?
I’m struggling with a similar issue on the 7-lymphoma case. It doesn’t have the models/deploy_train32.prototxt file referenced in the code. I tried using common/deploy_train32.prototxt but that one has 2 outputs while this is a 3-class problem. The weights file is also a 3-class one, so I get the same “cannot copy param 0” error when loading the model.
I tried changing the number of outputs to 3, and now I’m getting an error saying that the means shape is different from the input shape. Means shape is 3x36x36, while the input, as declared in the deploy file, is 10x3x32x32. Seems the model is expecting patches of a different size.
Thank you!
if you change the # of outputs in the deploy file final layer from 2 to 3, and add a crop_size of 32 to the data layer, the approach should work because caffe will randomly crop the image to the appropriate size. you can read more about it here http://caffe.berkeleyvision.org/tutorial/data.html. the mean file in the lymphoma directory is 36 x 36 x 3.
>>> means = a.data
>>> means = np.asarray(means)
>>> means.shape
(3888,)
36 *36 *3 = 3888
Yes the subdirectory does exist which is why I am confused as to what the problem is. Could you explain what the following line means?:
“scipy.misc.imsave(newfname_prob,outputimage_probs)”
I am confused about the “scipy.misc” portion. Thanks!
scipy image saving function: https://docs.scipy.org/doc/scipy-0.19.0/reference/generated/scipy.misc.imsave.html
hello, can i ask some questions about step3_make_dbs.sh?
when i run this script, i got the the following error:
E0625 22:53:41.458449 2865644480 io.cpp:80] Could not open or find file ./17077_1_0_e_331_0.png 0
E0625 22:53:41.459725 2865644480 io.cpp:80] Could not open or find file ./12880_1_0_b_670_0.png 0
E0625 22:53:41.460348 2865644480 io.cpp:80] Could not open or find file ./9124_1_1_p_1494_90.png 1
E0625 22:53:41.460801 2865644480 io.cpp:80] Could not open or find file ./17117_1_1_p_2193_90.png 1
E0625 22:53:41.460557 2865644480 io.cpp:80] Could not open or find file ./10273_1_0_e_8_0.png 0
E0625 22:53:41.461233 2865644480 io.cpp:80] Could not open or find file ./13616_1_1_p_1685_90.png
But i am pretty sure this png files are in the directory subs file, because i used the find command to find these png files, and found them.
can you help me out?
this script should be run *inside* of the subs directory. look at the command line parameters for convert_imageset and line up the directories depending on how you’ve set things up
i did not notice your reply, so i just comment the same question. sorry for that.
yes,I know the script in inside of the subs directory and that was i did.
$find /media/songhui/000AFAF600099DEC/nuclei -name step3.sh
/media/songhui/000AFAF600099DEC/nuclei/subs/step3.sh
if you look at the error message its saying “[filename] [label]” is not found. looking at the latest caffe source code (https://github.com/BVLC/caffe/blob/master/tools/convert_imageset.cpp#L80), it seems that they prefer spaces to tabs now. so you can either change all tabs in the file to spaces, or change the matlab file in step 2 to generate a new list using spaces instead of tabs. i’ve commited what are likely the necessary changes to the step2 file. overall though you should consider using the newer pipeline which is much faster and doesn’t require the seperate step
Hi, I seem to be unable to download the dataset – the link (http://gleason.case.edu/webdata/jpi-dl-tutorial/nuclei.tgz) in the post appears to be down. Do you have a mirror for the data? Thanks!
please try this updated link http://andrewjanowczyk.com/wp-static/nuclei.tgz
Hi Andrew, nice post. I had a question: how did you manually annotate the images?
either using aperio imagescope, imageviewer, a software platform called bisque, or histoview (available here http://engineering.case.edu/centers/ccipd/content/software)
What changes do I need to make in the code for Step 5? I have all the outputs of Step 1-4 in their folders. But I’m not that familiar with python, so I’m confused as to what specific changes need to be made.
no modifications to the script should be necessary as it accepts command line arguments. “BASE” is simply the sub-directory that the files are located in. so one could run python step5_output.py nuclei 1, and the results for fold 1 in the nuclei sub directory will be generated
Looks like we got it working now, thank you very much!
I’m trying to run Step 5 directly from Python.
I get the following error:
usage: step5_output.py [-h] base fold
step5_output.py: error: too few arguments
I think the following lines are responsible(given from the tutorial):
#parse the command line arguments
parser = argparse.ArgumentParser(description=’Generate full image outputs from Caffe DL models.’)
parser.add_argument(‘base’,help=”Base Directory type {nuclei, epi, mitosis, etc}”)
parser.add_argument(‘fold’,type=int,help=”Which fold to generate outputfor”)
args= parser.parse_args()
Anyone else encounter this problem? How can I fix this?
thanks for your guidance. it takes 6 hours for each test image. how can I just do the training one time?
thanks for your guidance.I just want to run nuclei segmentation code. I have run this code but it takes 6 hours to get result for each test image. how can I save trained model and don’t do training each time? maybe I don’t know how should I use it!
you only need to perform steps 1-4 once. from then on you can use step 5 to generate output code without reding the previous steps. since this is a pixel by pixel approach it is rather slow, you should consider looking at this post for an improved pipeline
Hi, I’m trying to run step 5 on a Amazon Web Services cloud. I think I’ve copied all the folders and files that Step 5’s python script needs onto the cloud. When I begin running it, however, I get the following error:
I0927 08:04:55.434144 9993 layer_factory.hpp:77] Creating layer input
I0927 08:04:55.434183 9993 net.cpp:84] Creating Layer input
I0927 08:04:55.434212 9993 net.cpp:380] input -> data
F0927 08:04:55.446313 9993 syncedmem.hpp:22] Check failed: error == cudaSuccess (30 vs. 0) unknown error
*** Check failure stack trace: ***
Aborted (core dumped)
Any idea how I can fix this?
this may help https://github.com/NVIDIA/DIGITS/issues/1663
Hi,
I’m encountering a issue with Step 5 running on an Amazon Web Services server with a gpu. Here is the following error:
I1001 10:27:41.528944 10085 net.cpp:744] Ignoring source layer loss
10262_500_f00357_original.tif
working on file: 10262_500_f00357_original.tif
Traceback (most recent call last):
File “data/data_copy_for_aws/scripts/step5_output_timing_aws.py”, line 87, in
scipy.misc.imsave(newfname_class, outputimage) #first thing we do is save a file to let potential other workers know that this file is being worked on and it should be skipped
File “/usr/local/lib/python2.7/dist-packages/scipy/misc/pilutil.py”, line 199, in imsave
im.save(name)
File “/usr/local/lib/python2.7/dist-packages/PIL/Image.py”, line 1890, in save
fp = builtins.open(filename, “w+b”)
IOError: [Errno 2] No such file or directory: ‘data/data_copy_for_aws/images/5/10262_500_f00357_original_class.png’
I understand the script was meant to create this .png file, but it seems like it doesn’t for some reason and I can’t quite pin down what is the issue.
Any ideas?
does the directory exist?
Everything up to ‘10262_500_f00357_original_class.png’ exists, and I understand that 10262_500_f00357_original_class.png’ was meant to be created by the script. It seems like the script doesn’t save this image and I’m not sure why.
that is indeed very strange. does the directory have write access to the python script? try making a python script which solely saves an empty image at that location and launching it from the same shell as the DL output script
Yeah, that did it! I realized you can only execute it from the furthermost folder. It fixed everything. Thanks!
Hi Andrew,
Thanks for this tutorial, it is really helpful. I have a question about overlapping nuclei in digital pathology images. Can you comment on this subject based on your experience? what are good methods? can we do deep learning directly to differentiate/quantify nuclei to one or more nuclei etc .. ? some references that you think are good are appreciated?
Overlapping nuclei tend to be very tough to deal with, but thankfully in many organs they aren’t very prevalent and thus can be treated as a single nuclei without impacting downstream applications. I think the first question is always to ask oneself what evidence there is, or can be created, to indicate that any additional refinement is necessary. While at CWRU we have developed a few cell splitting algorithms, people usually end up using something as simple as watershed to get a close approximation without it affecting too greatly downstream results. That said, a good general paper on nuclei is this http://ieeexplore.ieee.org/document/6690201/ . some of our work is here: https://www.spiedigitallibrary.org/conference-proceedings-of-spie/7962/1/Segmenting-multiple-overlapping-objects-via-a-hybrid-active-contour-model/10.1117/12.878425.short?SSO=1
I think it should be possible to easily use DL to be able to detect when nuclei has in fact overlapped (note: detection not segmentation), the real challenge is being able to get DL to actually separate the nuclei and provide their boundaries. While I think it has the capability of doing so, creating and annotating a dataset for training and measuring test results is quite laborious and in fact I don’t think one exists? In the end, deep learning becomes very easy to use when there is a sufficient datset, but finding/creating appropriate datasets seems to be the current bottlenecks.
please help me how to execute step 4. i find the solver.prototxt and train_val.prototxt at this link
https://github.com/BVLC/caffe/blob/master/models/bvlc_alexnet/solver.prototxt
https://github.com/BVLC/caffe/tree/master/models/bvlc_alexnet
please help me how to change this file. i m using 5 fold.
please read the blog post carefully, there is a link to github which has the correct files
hi andrew
thanks for your great works
would you please give some information about the datasets?
for example which institute or hospital collaborated on these!the iDC database i think is from “Hospital of the University of Pennsylvania and The Cancer Institute of New Jersey ”
but what about the others?
thanks alot
Thats a good question, i don’t know the answer to all of them off hand. IDC dataset is correct. Nuclei are from Upenn, lymphoma are from NIA and were introduced in their wnd-chrm paper. is there one in particular you’re interested in?
hi Dr,
actually, I am an MSc student and a researcher, I am interested in working with three of your datasets (Nuclei, Epithelium, Tubule).
but when I was checking to use the nuclei dataset for segmentation, I found that just some parts of the nucleus are annotated! so how could we use it? is it the final nucleus dataset?
thanks for helping and answering.
yes its the final dataset, unfortunately it takes too long to annotate all of the nuclei! you can read our paper to see how we developed an approach specifically for dealing with these partial annotations
We tried using our own images for segmentation after completed training with your models. Our images are also H&E stained pathology slides, however the contrast between nuclei and its background contents are much more clear in the TCGA-BRCA archive you’ve used. The nuclei in our slides are definitely visible, but our output only has 3-4 segmented nuclei. We would have to preprocess the image to work the models, however that kind of defeats the purpose. Have you encountered this issue? Would the only option be to train with our own slides?
you can try lowering the threshold on the output images, but that may result in additional false positives. i think this blog post i wrote will answer your questions: http://www.andrewjanowczyk.com/on-stain-normalization-in-deep-learning/
Thanks!
Do you have any more information regarding the specs of the scanned slides? I see that the magnification is 40x from the dataset you’ve used, but do you also have the slide’s pixel resolution?
this is the information i have from the header: ‘Aperio Image Library v10.0.44
98000×80213 [0,100 94147×80113] (256×256) JPEG/RGB Q=70|AppMag = 40|StripeWidth = 1000|ScanScope ID = SS5135|Filename = 8865|Date = 07/01/09|Time = 14:49:02|User = 11f6c28a-c25c-46a2-ab1e-5b736cf8a488|Parmset = COVERSLIP|MPP = 0.2514|Left = 33.100040|Top = 20.991980|LineCameraSkew = -0.000167|LineAreaXOffset = 0.000000|LineAreaYOffset = 0.000000|Focus Offset = 0.000000|DSR ID = AP5135-DSR|ImageID = 8865|OriginalWidth = 98000|Originalheight = 80213|ICC Profile = ScanScope v1’
Sir, you have used many functions in step 1. And the detail of those functions is not provided. I m not able to run the code of step 1 on my desktop.
Also can I use CNN on same dataset.
Thanks
what functions? also, this blog post is using a CNN
It is a great effort and very descriptive tutorial you perfectly clarify every step.
I just tried to download the dataset but when I extracted it it doesn’t open It gives me that the file type ( of the nuclei folder) is unknown
I wonder how I can open it ?
thank you for your kind concern
how are you trying to open it?
Please, I downloaded the file but the other file is not supported, how did you open it?
Sorry, not sure what file you’re talking about? As well, I think you may want to look at the Digital Pathology Segmentation using Pytorch + Unet version of this post which is updated to use pytorch
Hello dear, yes I wanted to take a look at the images (dataset), I extracted the zip file (1.5GB) but the file has no extension
it has a tgz file extension, you can use “Tar” to extract it
Hi sir, I’m trying to extract patches using Matlab but I have never used Matlab before could you please tell me what input should looks like.
As mentioned at the top of this blog pots, I wouldn’t use this matlab approach anymore, and in fact I don’t think you can follow this workflow since caffe won’t be supported with the current GPU drivers. You should use the python versions: Digital Pathology Segmentation using Pytorch + Unet or Digital pathology classification using Pytorch + Densenet
Hello,
Is there a specific license that you are sharing the public datasets under?
Many thanks.
I don’t think that crossed our mind when we were releasing them “open source”. BSD-3 clause is what we use for the software, and should be applicable here as well?